
چگونه Google از NLP برای درک بهتر عبارتهای جستجو و محتوا استفاده میکند؟ در اینجا درباره نقشی که پردازش زبان طبیعی در معناییتر کردن جستجوی گوگل میکند، خواهیم گقت. پردازش زبان طبیعی دری را برای جستجوی معنایی در گوگل باز کرد. متخصصان سئو باید تغییر به جستجوی مبتنی بر موجودیت را درک کنند زیرا این آینده جستجوی گوگل است. در این مقاله، به پردازش زبان طبیعی یا گوگل NLP و نحوه استفاده گوگل از NLP برای تفسیر جستجوها و جستجوهای محتوا، استخراج موجودیت ها و موارد دیگر خواهیم پرداخت.
پردازش زبان طبیعی چیست؟

پردازش زبان طبیعی یا NLP درک معنای کلمات، جملات و متون را برای پردازش ممکن میسازد. که شامل درک زبان طبیعی (NLU)، که امکان تفسیر معنایی متن و زبان طبیعی را می دهد، و تولید زبان طبیعی (NLG) است.
NLP را می توان برای موارد زیر استفاده کرد:
- تشخیص گفتار (متن به گفتار و گفتار به متن).
- تقسیم بندی گفتار ضبط شده قبلی به کلمات، جملات و عبارات فردی.
- شناسایی اشکال اساسی کلمات و به دست آوردن اطلاعات گرامری.
- تشخیص کارکرد تک تک کلمات در یک جمله (موضوع، فعل، فاعل، مقاله و غیره)
- استخراج معنی جملات و بخشهایی از جملات یا عبارات، مانند جملههای صفتی (مثلاً “خیلی طولانی”)، عبارات اضافه (مثلاً “به رودخانه”)، یا عبارات اسمی (مثلاً “پایان طولانی”).
- شناسایی زمینه های جمله، روابط جمله و موجودیت ها
- تجزیه و تحلیل متن زبانی، تجزیه و تحلیل احساسات، ترجمه ها (از جمله موارد مربوط به دستیاران صوتی)، ربات های مکالمه و سیستم های پرسش و پاسخ اولیه.
در اینجا اجزای اصلی NLP آمده است:
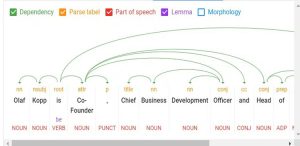
نگاهی به API پردازش زبان طبیعی گوگل:
- Tokenization: جمله را به عبارات مختلف تقسیم می کند.
- Word type labeling: برای طبقه بندی کلمات بر اساس مفعول، موضوع، صفت و غیره.
- Word dependencies: روابط بین کلمات را بر اساس قواعد دستور زبان تعریف می کند.
- Lemmatization: تعیین اینکه آیا یک کلمه دارای اشکال مختلف است یا خیر و عادی سازی تفاوت ها در شکل اصلی. به عنوان مثال، شکل اصلی کلمه “car” “cars” است.
- Parsing labels: کلمات را بر اساس رابطه بین دو کلمه متصل به یک وابستگی برچسب گذاری می کند.
- Named entity analysis and extraction: کلماتی را با معنای “شناخته” شناسایی می کند و آنها را به کلاس هایی از انواع موجودیت اختصاص می دهد. به طور کلی، موجودیت های نامگذاری شده سازمان ها، افراد، محصولات، مکان ها و اسم ها هستند. در یک جمله، موضوعات و اشیاء باید به عنوان موجودیت شناسایی شوند.
تجزیه و تحلیل موجودیت با استفاده از Google Natural Processing API
- Salience scoring: تعیین می کند که متن چقدر با موضوع مرتبط است. برجستگی عموماً با استناد رایج کلمات در وب و روابط بین موجودیتها در پایگاههای داده مانند ویکیپدیا و فریبیس تعیین میشود. متخصصان سئو روش مشابهی را از تجزیه و تحلیل TF-IDF نیز می توانند به دست آورند.
- Sentiment analysis: نظر (نظر یا موضع) بیان شده در متن در مورد موجودیت ها یا موضوعات را مشخص می کند.
- Text categorization: در سطح کلان، NLP متن را به دسته بندی محتوا طبقه بندی می کند. طبقه بندی متن به تعیین موضوع متن به طور کلی کمک می کند.
- Text classification and function: NLP می تواند جلوتر رفته و عملکرد یا هدف مورد نظر محتوا را تعریف کند. تطبیق هدف جستجو با یک سند بسیار جالب است.
- Content type extraction: بر اساس الگوهای ساختاری یا زمینه، موتور جستجو می تواند نوع محتوای متن را بدون داده های ساختاریافته تعیین کند. HTML متن، قالببندی و نوع داده (تاریخ، مکان، URL و غیره) میتواند بدون استفاده از برچسبها تعیین کند که آیا این یک دستور غذا، محصول، رویداد یا نوع محتوای دیگری است.
- Identify implicit meaning based on structure: قالب بندی متن می تواند معنای ضمنی آن را تغییر دهد. سرفصل ها، خطوط شکسته، فهرست ها و مجاورت، درک ثانویه ای از متن را منتقل می کنند. به عنوان مثال، زمانی که متن در یک لیست مرتب شده HTML یا در یک سری آدرس با اعداد در جلوی آن نمایش داده می شود، احتمالاً یک لیست یا یک سفارش است. ساختار نه تنها با تگ های HTML بلکه با اندازه/ضخامت خط قابل مشاهده و مجاورت در حین رندر تعریف می شود.
استفاده از NLP در search

سال ها است که گوگل مدلهای زبانی مانند BERT یا MUM را برای تفسیر متن، جستوجو، و حتی محتوای ویدیویی و صوتی پرورش داده است. این مدل ها با پردازش زبان طبیعی تغذیه می شوند. جستجوی گوگل عمدتاً از پردازش زبان طبیعی در زمینه های زیر استفاده می کند:
- تفسیر سوالات جستجو
- طبقه بندی موضوع و هدف اسناد.
- تجزیه و تحلیل موجودیت ها در اسناد، پرس و جوهای جستجو و پست های رسانه های اجتماعی.
- ایجاد قطعه ها و پاسخ های ویژه در جستجوی صوتی.
- تفسیر محتوای صوتی و تصویری.
- گسترش و بهبود نمودار دانش (Knowledge Graph).
گوگل هنگام انتشار بهروزرسانی BERT در اکتبر 2019 بر اهمیت درک زبان طبیعی در جستجو تأکید کرد:
“تحقیق اساساً در مورد درک زبان است. کار ما این است که بدانیم به دنبال چه چیزی هستید و اطلاعات مفیدی را از وب نمایش دهیم، مهم نیست که کلمات چگونه املا یا در جستجوی شما گنجانده شده اند. در حالی که ما به بهبود خود ادامه داده ایم. درک زبان در طول سالها، ما در برخی موارد هستیم گاهی اوقات هنوز درست متوجه نمیشویم، بهخصوص در مورد پرسشهای پیچیده یا پرسوجوهای مکالمه. در واقع، این یکی از دلایلی است که مردم از کلمات کلیدی استفاده میکنند و رشتههایی از کلمات را که فکر میکنند مینویسند. ما متوجه خواهیم شد، اما در واقع این طور نیست که آنها مطرح می کنند.” شاید این مقاله نیز برای شما مفید باشد: E-A-T گوگل چیست؟
استفاده از NLP در تفسیر سوالات و اسناد جستجو
گفته می شود BERT مهم ترین پیشرفت در جستجوی گوگل در چند سال پس از RankBrain است. بر اساس NLP، به روز رسانی برای بهبود تفسیر پرس و جو طراحی شده است و در ابتدا بر 10٪ از تمام درخواست های جستجو تأثیر می گذارد. BERT نه تنها در تفسیر پرس و جو بلکه در ترتیب و گروه بندی قطعات برجسته و همچنین تفسیر پرسشنامه های متنی در اسناد نقش دارد. با استفاده از مدلهای BERT برای رتبهبندی و تکههای برجسته در جستجو، میتوانیم کار بسیار بهتری برای کمک به شما در یافتن اطلاعات مفید انجام دهیم. در واقع، وقتی نوبت به رتبهبندی نتایج میرسد، BERT به «جستجو» کمک میکند تا یکی از آنها را بفهمد. اعلام شد که بهروزرسانی MUM در Search On ’21 منتشر خواهد شد. همچنین بر اساس NLP، MUM چند زبانه است، به سوالات جستجوی پیچیده با داده های چند رسانه ای پاسخ می دهد و اطلاعات را از فرمت های رسانه های مختلف پردازش می کند. MUM علاوه بر متن، فایل های تصویری، ویدئویی و صوتی را نیز درک می کند. MUM چندین فناوری را ترکیب میکند تا جستجوهای Google را معناییتر کند. با MUM، گوگل میخواهد به پرسشهای جستجوی پیچیده با فرمتهای رسانهای مختلف پاسخ دهد تا کاربر را در طول جستجو درگیر کند. همانند BERT و MUM، NLP یک گام اساسی برای درک معنایی بهتر و یک موتور جستجوی کاربر محورتر است. درک عبارتهای جستجو و محتوا در موجودیتها نشانه تغییر از «رشتهها» به «اسم» است. هدف گوگل ایجاد درک معنایی از عبارتهای جستجو و محتوا است. با مشخص کردن موجودیت ها در پرس و جوهای جستجو، معنی و هدف جستجو واضح تر می شود. تک تک کلمات عبارت جستجو دیگر به تنهایی نیستند، بلکه در متن کل عبارت جستجو در نظر گرفته می شوند. جادوی تفسیر عبارات جستجو در پردازش پرس و جو اتفاق می افتد. مراحل زیر در اینجا مهم است:
- هدفی که عبارت جستجو در آن قرار دارد را تعیین کنید. اگر زمینه هدف واضح باشد، Google میتواند مجموعه محتوایی از اسناد متنی، ویدئوها و تصاویر را به عنوان نتایج جستجوی مرتبط بالقوه شناسایی کند. این امر به ویژه در مورد عبارات جستجوی مبهم دشوار است. شناسایی موجودیت ها و معنای آنها در عبارت جستجو (Named Entity Recognition).
- معنای مفهومی یک عبارت جستجو را درک کنید.
- هدف سرچ را مشخص کنید.
- توضیح معنایی عبارت جستجو
- عبارت جستجوی خود را اصلاح کنید
NLP مهمترین روش برای استخراج مفهوم است
پردازش زبان طبیعی مهمترین نقش را برای گوگل در شناسایی موجودیت ها و معانی آنها ایفا می کند و استخراج هدف از داده های بدون ساختار را ممکن می سازد. بر این اساس، روابط بین موجودیت ها و نمودار دانش می تواند ایجاد شود. برچسب گذاری گفتار تا حدی به این امر کمک می کند. اسم ها موجودیت های بالقوه هستند و افعال اغلب نشان دهنده رابطه موجودیت ها با یکدیگر هستند. صفت ها یک موجود را توصیف می کنند و قیدها یک رابطه را توصیف می کنند. شاید این مقاله نیز برای شما مفید باشد: سئو صفحات PLP و PDP
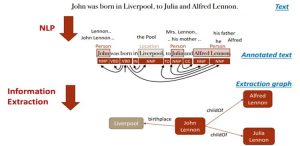
نمونه ای از NLP برای ساختن یک نمودار شناختی: استخراج نمودارهای شناختی از متن
گوگل تاکنون تنها از اطلاعات حداقلی و بدون ساختار برای تغذیه نمودار دانش استفاده کرده است. موارد زیر را می توان فرض کرد:
- موجودیت هایی که تاکنون در نمودار دانش ثبت شده اند، فقط tip of the iceberg هستند.
- علاوه بر این، گوگل یک مخزن دیگر از دانش را با اطلاعات long-tail entities تغذیه می کند.
- برنامه نویسی عصبی زبانی (NLP) نقش اصلی را در تغذیه این مخزن دانش ایفا می کند.
گوگل در حال حاضر در NLP بسیار خوب است اما در ارزیابی اطلاعات استخراج شده به صورت خودکار برای دقت به نتایج، رضایت بخش نبوده است. استخراج داده ها برای پایگاه داده دانش مانند نمودار دانش از داده های بدون ساختار مانند وب سایت ها پیچیده است. علاوه بر کامل بودن اطلاعات، صحت آن ضروری است. امروزه گوگل از طریق NLP کامل بودن را در مقیاس بزرگ تضمین می کند، اما اثبات اعتبار و دقت دشوار است. شاید به همین دلیل است که گوگل هنوز در مورد موقعیتیابی مستقیم اطلاعات در مورد موجودیتهای طولانی در SERP با احتیاط رفتار میکند.
شاخص مبتنی بر نهاد در مقابل شاخص کلاسیک مبتنی بر محتوا
معرفی به روز رسانی مرغ مگس خوار راه را برای تحقیقات معنایی هموار کرد. همچنین نمودار دانش را برجسته می کند. نمودار دانش، شاخص نهادهای گوگل است. تمام ویژگیها، اسناد و تصاویر دیجیتالی مانند فایلهای شخصی و دامنههای مربوط به موجودیت در یک فهرست مبتنی بر موجودیت سازماندهی شدهاند.
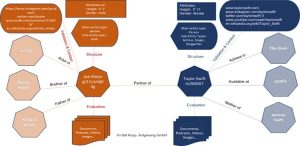
نمونهای از نحوه عملکرد Google Entity Index و Classic Index.
نمودار دانش در حال حاضر به موازات شاخص کلاسیک رتبه گوگل استفاده می شود. فرض کنید گوگل در پرس و جو شناسایی می کند که مربوط به یک نهاد ثبت شده در نمودار دانش است. در این حالت به اطلاعات هر دو شاخص با تمرکز بر موجودیت دسترسی پیدا می کند و کلیه اطلاعات و مدارک مربوط به نهاد مورد توجه قرار می گیرد. یک رابط یا API بین نشانگر کلاسیک Google و یک نمودار دانش، یا نوع دیگری از مخزن دانش، برای تبادل اطلاعات بین دو شاخص مورد نیاز است. این رابط محتوای موجودیت همه چیز در مورد سرچ است است:
- اینکه آیا در یک محتوا موجودیت هایی وجود دارد.
- اینکه آیا نهاد اصلی مرتبط با محتوا وجود دارد یا خیر.
- به چه هدفی می توان موجودیت اصلی را اختصاص داد.
- یعنی نویسنده یا نهادی که محتوا به آن اختصاص داده شده است.
- چگونگی ارتباط اسامی موجود در محتوا با یکدیگر.
- ویژگی یا ویژگی هایی که باید به موجودیت ها نسبت داده شوند.
می تواند به این شکل باشد:
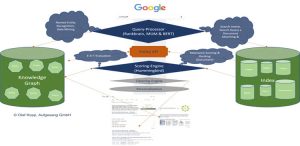
نمونه ای از رابط محتوای موجودیت.
ما تازه شروع به احساس تأثیر جستجوی مبتنی بر موجودیت در SERP کردهایم، زیرا گوگل در درک معنای موجودیتهای فردی کند است. موجودیت ها از بالا به پایین به ترتیب اهمیت اجتماعی درک می شوند. مرتبط ترین آنها به ترتیب در ویکی داده و ویکی پدیا ثبت شده است. وظیفه بزرگ شناسایی و راستیآزمایی نهادهای طولانی مدت خواهد بود. همچنین مشخص نیست که گوگل چه معیارهایی را برای گنجاندن یک موجودیت در نمودار دانش بررسی می کند. در یک سمینار وب مستر آلمانی در ژانویه 2019، جان مولر از گوگل گفت که آنها در حال کار بر روی روشی ساده تر برای ایجاد موجودیت برای همه هستند. “فکر نمیکنم پاسخ روشنی داشته باشیم. فکر میکنم ما الگوریتمهای مختلفی داریم که چیزی شبیه به این را بررسی میکنند و سپس از معیارهای مختلفی برای کنار هم قرار دادن همه چیز استفاده میکنند، آنها را جدا میکنند و چیزهایی را که واقعاً موجودیتهای مجزا هستند را تشخیص میدهند. اما من نمیدانم دقیقاً چه برنامهای وجود دارد.» NLP نقش حیاتی در بالا بردن سطح این چالش ایفا می کند. مثالهای دموی diffbot نشان میدهد که NLP چقدر میتواند برای استخراج موجودیتها و ایجاد یک نمودار دانش استفاده شود. سئو سایت
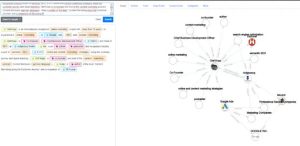
نمونه هایی از نمای diffbot.
Google Search NLP

RankBrain برای تفسیر عبارات و عبارات جستجو با تجزیه و تحلیل فضای برداری که قبلاً به این روش استفاده نشده است، معرفی شده است. BERT و MUM از پردازش زبان طبیعی برای تفسیر سوالات و اسناد جستجو استفاده می کنند. علاوه بر تفسیر جستجو و جستجوهای محتوا، MUM و BERT دری را برای اجازه دادن به پایگاه داده دانش مانند نمودار دانش برای رشد در مقیاس باز کردند و در نتیجه جستجوی معنایی را در Google توسعه دادند. پیشرفتهای جستجوی Google از طریق بهروزرسانیهای اصلی نیز با MUM ،BERT و در نهایت NLP و جستجوی معنایی مرتبط است. در آینده، ما شاهد نتایج جستجوی Google مبتنی بر نهادهای بیشتری خواهیم بود تا جایگزین نمایه سازی و رتبه بندی بر اساس عبارات کلاسیک شوند.
مقاله تخصصی و سطح بالایی بود مرسی
مرسی از نظر لطف تون
به نظرتون nlp به طور تخصصی تمامی آپدیت هاش روی فارسی اعمال میشه؟
واقعا خودمم هم اینو دقیق نمیدونم. ولی اینکه روی زبان فارسی کار میکنه، قطعا کار میکنه
عالی بود ممنون
مرسی از نظر تون
کامل جامع بود
مرسی از توجه تون